Elasticsearch 简明指南
本文简单讲解了 Elasticsearch 的基本概念,介绍了如何使用 docker compose 搭建 Elasticsearch 和 Kibana 环境,同时介绍了那些 Elasticsearch 常用的 API,最后介绍了如何使用 Go 语言操作 Elasticsearch。
Elasticsearch
介绍
Elasticsearch 是一个高度可扩展的开源实时搜索和分析引擎,它允许用户在近实时的时间内执行全文搜索、结构化搜索、聚合、过滤等功能。Elasticsearch 基于 Lucene 构建,提供了强大的全文搜索功能,并且具有广泛的应用领域,包括日志和实时分析、社交媒体、电子商务等等。
Elasticsearch 为所有类型的数据提供近乎实时的搜索和分析。无论是结构化文本还是非结构化文本、数字数据或地理空间数据,Elasticsearch 都能够以快速搜索的方式有效地存储和索引它们。除了简单的数据检索和聚合信息之外,还可以用 Elasticsearch 发现数据中的趋势和模式。随着数据和查询量的增长,Elasticsearch 的分布式特性能够横向扩展至数以百计的服务器存储以及处理PB级的数据,同时可以在极短的时间内索引、搜索和分析大量的数据。
Elasticsearch 能做什么
虽然不是每个问题都是搜索问题,但 Elasticsearch 在各种用例中提供了处理数据的速度和灵活性:
- 为 APP 或网站增加搜索功能
- 存储和分析日志、指标和安全事件数据
- 使用机器学习实时自动建模数据的行为
- 使用 Elasticsearch 作为存储引擎自动化业务工作流
- 使用 Elasticsearch 作为地理信息系统(GIS)管理、集成和分析空间信息
- 使用 Elasticsearch 作为生物信息学研究工具存储和处理遗传数据
基本上,Elasticsearch 已经渗透到了我们工作和生活的方方面面。我们打开电商网站搜索商品、打开 APP 查询资料,或者工作上使用 EFK 搭建日志系统等,这背后都有 Elasticsearch 的贡献。对了,Github 的搜索功能也是基于 Elasticsearch 构建起来的。
Elasticsearch 架构与工作原理
架构概述
Elasticsearch 架构主要由三个组件构成:索引、分片和节点。
- 索引是文档的逻辑分组,类似于数据库中的表;
- 分片是索引的物理分区,用于提高数据分布和查询性能;
- 节点是运行 Elasticsearch 的服务器实例。
工作原理
Elasticsearch 通过以下步骤完成搜索和分析任务:
- 接收用户查询请求:Elasticsearch 通过 RESTful API 或 JSON 请求接收用户的查询请求。
- 路由请求:接收到查询请求后,Elasticsearch 根据请求中的索引和分片信息将请求路由到相应的节点。
- 执行查询:节点执行查询请求,并在相应的索引中查找匹配的文档。
- 返回结果:查询结果以 JSON 格式返回给用户,包括匹配的文档和相关字段信息。
Elasticsearch 基本概念
索引(Index)
在 Elasticsearch 中,索引是存储相关数据的数据结构,可以理解为数据库中的表。索引是通过对数据源进行索引创建的,它是一种对数据进行结构化和半结构化处理的结果。每个索引都有自己的映射(mapping),用于定义每个字段的数据类型和其他属性。
在 Elasticsearch 中,索引是存储相关数据的数据结构,可以理解为数据库中的表。索引是通过对数据源进行索引创建的,它是一种对数据进行结构化和半结构化处理的结构结果。每个索引都有自己的映射(mapping),用于定义每个字段的数据类型和其他属性。
索引的映射(mapping)是用于定义索引中每个字段的数据类型和其他属性。在创建索引时,需要定义每个字段的数据类型(如文本、数字、日期等)和其他属性(如是否需要分析、是否存储等)。此外,映射还可以定义其他搞基功能,如聚合、排序和过滤等。
类型(Type)
在早期版本的 Elasticsearch 中,类型(type)是一个非常重要的概念。每个索引内部都可以有多个类型,而每个类型又可以存储多个文档。类型实际上是索引内部的一种逻辑分区,通过类型名称在索引内进行唯一标识。
在索引和类型之间,我们可以把类型看作是表,索引看作是数据库。在创建索引的时候,可以指定一个或多个类型。类型的作用在于把索引中的数据按照一定的逻辑进行分类,从而方便后期的数据检索和分析。
每个类型下又可以存储多个文档,每个文档都有一个唯一的ID作为区分,以JSON格式来表示。在存储文档时,需要指定文档所属的类型和索引名称,同时还可以为文档指定一个或多个字段。字段可以是不同的数据类型,如文本、数字、日期等。
然而,需要注意的是,从 Elasticsearch 7.x 版本开始,索引中的每个文档都直接属于一个索引,而不再需要指定类型。这主要是为了简化索引和查询操作,提高查询效率。因此,在新的版本中,类型这个概念已经逐渐被淘汰。
文档(Document)
文档是 Elasticsearch 中存储和检索的基本单位,它是序列化为 JSON 格式的数据结构。每个文档都有一个唯一的标识符,称为 _id 字段,用于唯一标识该文档。每个文档都存储在一个索引中,并且可以包含多个字段,这些字段可以是不同的数据类型,如文字、数字、日期等。
在 Elasticsearch 中,文档的属性包括 _index、_type 和 _source 等。_index表示文档所属的索引名称,_type 表示文档所属的类型名称(在早期的 Elasticsearch 版本中,这是必需的,但在 7.x 版本之后已经不再需要),_source 表示文档的原始 JSON 数据。
当我们在 Elasticsearch 中执行搜索查询时,实际上是在查询文档。我们可以使用简单的关键字搜索,也可以使用复杂的查询语句来搜索多个字段。在搜索时,Elasticsearch 会使用反向索引来快速定位匹配的文档。反向索引是一个为每个字段建立的倒排索引,它允许 Elasticsearch 根据关键词在字段中快速查找包含该关键词的文档。
Elasticsearch 集群基本概念
集群(Cluster)
一个 Elasticsearch 集群通常包含了多个节点(Node)和一个或多个索引(Index),并且这些节点和索引共同构成了整个 Elasticsearch 集群,在所有节点上提供联合索引和搜索功能。
每个 Cluster 都有一个唯一的名称,即 cluster name,它用于标识和区分不同的 Elasticsearch 集群。
节点(Node)
在 Elasticsearch 集群中,Node 是指运行 Elasticsearch 实例的服务器。每个 Node 都有自己的名称和标识符,并且都有自己的数据存储和索引存储。
一个 Elasticsearch 集群由一个或多个 Node 组成,这些 Node 通过它们的集群名称进行标识。在默认情况下,如果 Elasticsearch 已经开始运行,它会自动生成一个叫做“elasticsearch”的集群。我们也可以在配置文件(elasticsearch.yml)中定制我们的集群名字。
Node 在 Elasticsearch 中扮演着不同的角色。根据节点的配置和功能,可以将 Node 分为以下几种类型:
- Master Node:负责整个 Cluster 的配置和管理任务,如创建、更新和删除索引,添加或删除 Node 等。一个 Cluster 中至少需要有一个 Master Node。
- Data Node:主要负责数据的存储和处理,它们可以处理数据的 CRUD 操作、搜索操作、聚合操作等。一个 Cluster 中可以有多个 Data Node。
- Ingest Node:主要负责对文档进行预处理,如解析、转换、过滤等操作,然后再将文档写入到 Index 中。每个 Cluster 中至少需要有一个 Ingest Node。除了上述的三种类型外,还可以有 Tribe Node、Remote Cluster Client 等特殊用途的 Node。
Node 之间是对等关系(去中心化),每个节点上面的集群状态数据都是实时同步的。如果 Master 节点出故障,按照预定的程序,其他一台 Node 机器会被选举称为新的 Master。
需要注意的是,一个 Node 可以同时拥有一种或几种功能,如一个 Node 可以同时是 Master Node 和 Data Node。
分片(Shards)
在 Elasticsearch 中,Shards 是索引的分片,每个 Shard 都是一个基于 Lucene 的索引。当索引的数据量太大时,由于内存的限制、磁盘处理能力不足、无法足够快的相应客户端的请求等,一个节点可能不太够用。这种情况下,数据可以被分为较小的分片,每个分片放到不同的服务器上。每个分片可以有零个或多个副本。这不仅能够提高查询效率,还能够提高系统的可靠性和可用性。如果某个节点或 Shard 发生故障,Elasticsearch 可以从其他节点或 Shard 的副本中恢复数据,从而保证数据的可靠性和可用性。
每个 Shard 都存储在集群中的某个节点上,每个节点可以存储一个或多个 Shard。当查询一个索引时,Elasticsearch 会在所有的 Shard 上执行查询,并将结果合并返回给用户。
对于每个索引,在创建时需要指定主分片的数量,一旦索引创建后,主分片的数量就不能更改。
副本(Replicas)
在 Elasticsearch 中,Replicas 是指索引的副本。它们的作用主要有两点:
- 提高系统的容错性。当某个节点发生故障,或者某个分片(Shard)损坏或丢失时,可以从副本中恢复数据。这意味着,即使一个节点或分片出现问题,也不会导致整个索引的数据丢失。这种机制可以增加系统的可靠性,并减少因节点或分片故障导致的宕机时间。
- 提高查询效率。Elasticsearch 会自动对搜索请求进行负载均衡,可以将搜索请求分配到多个节点上,从而并行处理搜索请求,提高查询效率。这种负载均衡机制可以在节点之间分发查询请求,使得每个节点都可以处理一部分查询请求,从而避免了一个节点的瓶颈效应。
需要注意的是,在 Elasticsearch 中,每个索引可以有多个副本(Replicas),但是每个副本只能由一个主分片(Primary Shard)。可以增加或删除副本的数量。
Elasticsearch 基本概念与关系型数据库的参考对比
| ES概念 | 关系型数据库 |
|---|---|
| Index(索引)支持全文检索 | Table(表) |
| Doucment(文档),不同文档可以有不同的字段集合 | Row(数据行) |
| Field(字段) | Column(数据列) |
| Mapping(映射) | Schema(模式) |
搭建 Elasticsearch 环境
这里使用 docker compose 快速搭建一套 Elasticsearch 和 Kibana 环境。
为什么要带 Kibana?
因为 Kibana 提供了一个好用的开发者控制台,非常适合用来练习 Elasticsearch 命令。
version: "3.7"
services:
elasticsearch:
container_name: elasticsearch
image: docker.elastic.co/elasticsearch/elasticsearch:8.9.1
environment:
- node.name=elasticsearch
- ES_JAVA_OPTS=-Xms512m -Xmx512m
- discovery.type=single-node
- xpack.security.enabled=false
ports:
- 9200:9200
- 9300:9300
networks:
- elastic
kibana:
image: docker.elastic.co/kibana/kibana:8.9.1
container_name: kibana
ports:
- 5601:5601
networks:
- elastic
depends_on:
- elasticsearch
networks:
elastic:将上面的内容保存至本地的docker-compose.yml文件,并在相同目录下执行以下命令启动容器。
docker-compose up待容器启动后,在本机浏览器打开http://127.0.0.1:5601/即可看到如下 kibana 管理界面。
点击页面上的“Explore on my own”按钮进入管理后台。
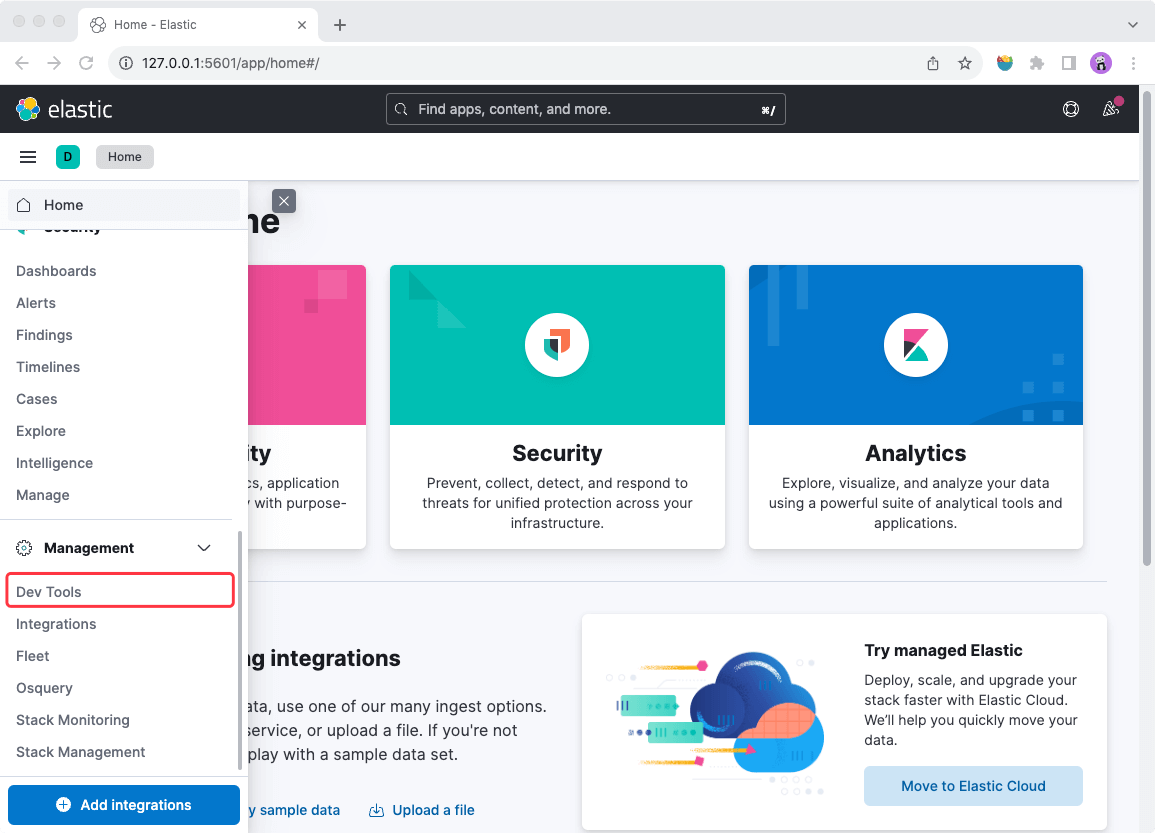
点击页面左侧的菜单栏,下滑找到“Management”菜单,点击“Dev Tools”即可打开如下开发工具。
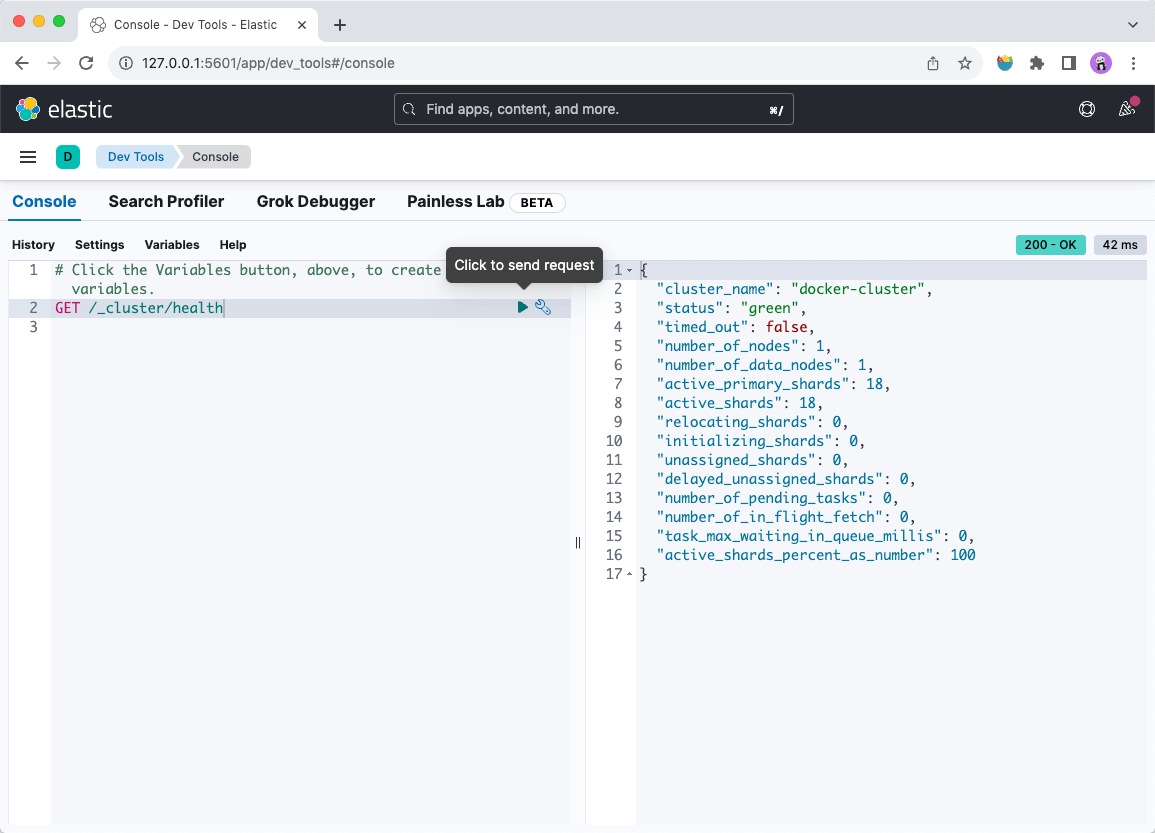
后续我们就可以在页面左侧窗口中输入curl命令,点击“▶”符号发送请求后,在页面右侧窗口查看返回结果。
例如,上图中执行了GET /_cluster/health命令,页面右侧返回了 Elasticsearch 集群的健康状态。
Elasticsearch REST APIs
对于没有任何 elasticsearch 基础的同学,强烈建议先阅读一下Elasticsearch:权威指南,了解关于 Elasticsearch 的基础概念。(这本书基于 Elasticsearch 2.x版本,有些内容可能已经过时。但不影响用来了解关于 Elasticsearch 的基本概念)
本节只介绍 Elasticsearch 中常用的 REST API,完整 REST API 内容请查看官方文档。
假设我们要搭建一个电商评价的审核服务,用户发表的评价数据格式如下。
{
"id":3,
"userID":147982603,
"score":1,
"status":2,
"publishTime":"2023-09-09T16:27:42.499144+08:00",
"content":"这是一个差评!",
"tags":[
{
"code":7000,
"title":"差评"
}
]
}以下 REST API 示例命令均为Kibana Dev Console中使用。
查看健康状态
输入以下命令可查看 Elasticsearch 集群的健康状态。
Kibana Dev Console 输入以下命令:
GET /_cat/health?v或将上述命令转为 curl 命令在终端执行。
curl -X GET "127.0.0.1:9200/_cat/health?v"输出:
epoch timestamp cluster status node.total node.data shards pri relo init unassign pending_tasks max_task_wait_time active_shards_percent
1694525220 13:27:00 docker-cluster yellow 1 1 19 19 0 0 1 0 - 95.0%查询所有索引
输入以下命令可查看 Elasticsearch 集群所有的索引。
GET /_cat/indices?v创建索引
创建索引的请求格式如下:
PUT /<index>
例如,下面的命令是在 Elasticsearch 集群创建一个名为my-index的新索引。
PUT /my-index在创建索引时还可以指定以下内容:
- 索引的设置(setting)
- 索引中字段的映射(mapping)
- 索引别名(alias)
例如
PUT /review-1
{
"settings": {
"number_of_replicas": 1
},
"mappings": {
"properties": {
"id":{
"type": "long"
},
"userID":{
"type": "long"
},
"score":{
"type": "integer"
},
"status":{
"type": "integer"
},
"content":{
"type": "text"
},
"publishTime":{
"type": "date"
},
"tags":{
"type": "nested",
"properties": {
"code":{
"type": "keyword"
},
"title":{
"type": "text"
}
}
}
}
},
"aliases": {
"review_1": {}
}
}删除索引
删除索引的请求格式如下:
DELETE /<index>
例如,输入以下命令来删除上面创建的my-index索引。
DELETE /my-index创建文档
将 JSON 文档添加到指定的数据流或索引并使其可搜索。如果目标是索引并且文档已经存在,则请求更新文档并递增其版本。
PUT /<target>/_doc/<_id>
POST /<target>/_doc/
PUT /<target>/_create/<_id>
POST /<target>/_create/<_id>
POST /review-1/_create/1
{
"id":1,
"userID":147982601,
"score":5,
"status":2,
"publishTime":"2023-09-09T16:07:42.499144+08:00",
"content":"这是一个好评!",
"tags":[
{
"code":1000,
"title":"好评"
},
{
"code":2000,
"title":"物超所值"
},
{
"code":3000,
"title":"有图"
}
]
}判断文档是否存在
HEAD /review-1/_doc/1如果存在,Elasticsearch 返回200 - OK的响应码,如果不存在则返回404 - Not Found。
获取文档
GET /review-1/_doc/1返回整个文档的内容,包括元数据。
{
"_index": "review-1",
"_id": "1",
"_version": 1,
"_seq_no": 0,
"_primary_term": 1,
"found": true,
"_source": {
"id": 1,
"userID": 147982601,
"score": 5,
"status": 2,
"publishTime": "2023-09-09T16:07:42.499144+08:00",
"content": "这是一个好评!",
"tags": [
{
"code": 1000,
"title": "好评"
},
{
"code": 2000,
"title": "物超所值"
},
{
"code": 3000,
"title": "有图"
}
]
}
}获取数据
GET /review-1/_source/1返回数据。
{
"id": 1,
"userID": 147982601,
"score": 5,
"status": 2,
"publishTime": "2023-09-09T16:07:42.499144+08:00",
"content": "这是一个好评!",
"tags": [
{
"code": 1000,
"title": "好评"
},
{
"code": 2000,
"title": "物超所值"
},
{
"code": 3000,
"title": "有图"
}
]
}获取指定手段
可以在查询时指定查询的具体字段。
GET /review-1/_source/1?_source=content,score返回
{
"score": 5,
"content": "这是一个好评!"
}更新文档
更新文档的请求格式如下:
POST /<index>/_update/<_id>
例如,下面的命令用于更新_id为1的文档。
POST /review-1/_update/1
{
"doc": {
"content": "这是修改过的好评!"
}
}返回updated表示更新成功。
{
"_index": "review-1",
"_id": "1",
"_version": 2,
"result": "updated",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 8,
"_primary_term": 1
}批量获取
命令格式:
GET /_mget
GET /<index>/_mget
GET /review-1/_mget
{
"docs":[
{
"_id":"1"
},
{
"_id":"2"
}
]
}删除文档
DELETE /review-1/_doc/1检索
返回与请求中定义的查询匹配的搜索结果。
支持的检索请求格式:
GET /<target>/_search
GET /_search
POST /<target>/_search
POST /_search
查询userID=147982601的文档。
GET /review-1/_search
{
"query": {
"bool": {
"filter":{
"term":{"userID": 147982601}
}
}
}
}查询publishTime<=2023-09-09T16:20:00+08:00的文档。
GET /review-1/_search
{
"query": {
"bool": {
"filter": [
{
"range": {
"publishTime": {
"lte": "2023-09-09T16:20:00+08:00"
}
}
}
]
}
}
}查询content中包含差评的文档。
GET /review-1/_search
{
"query": {
"match_phrase": {
"content": "差评"
}
}
}获取数量
用于获取搜索查询的匹配数量的请求格式如下。
GET /<target>/_count
例如,查询content中包含差评的文档数量。
GET /review-1/_count
{
"query": {
"match_phrase": {
"content": "差评"
}
}
}聚合
查询评价的平均分数。
POST /review-1/_search?size=0
{
"aggs": {
"avg_score": { "avg": { "field": "score"} }
}
}返回结果
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 5,
"relation": "eq"
},
"max_score": null,
"hits": []
},
"aggregations": {
"avg_score": {
"value": 3.8
}
}
}查询每个标签下的评价数。
GET /review-1/_search
{
"size": 0,
"aggs": {
"tagList": {
"nested": {
"path": "tags"
},
"aggs": {
"tagCount":{
"terms": {
"field": "tags.code",
"size": 10
}
}
}
}
}
}返回
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 5,
"relation": "eq"
},
"max_score": null,
"hits": []
},
"aggregations": {
"tagList": {
"doc_count": 9,
"tagCount": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": "1000",
"doc_count": 3
},
{
"key": "3000",
"doc_count": 3
},
{
"key": "2000",
"doc_count": 1
},
{
"key": "6000",
"doc_count": 1
},
{
"key": "7000",
"doc_count": 1
}
]
}
}
}
}ES go 客户端
Elasticsearch 官方 Go 客户端的使用请查看go-elasticsearch 使用指南。